Thread
线程生命周期
happens-before
- 程序顺序规则:一个线程中的每一个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start规则:如果线程A执行操作ThreadB.start()启动线程B,那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作、
- join规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
内存屏障
如果第一个操作是volatile读,那无论第二个操作是什么,都不能重排序;
如果第二个操作是volatile写,那无论第一个操作是什么,都不能重排序;
如果第一个操作是volatile写,第二个操作是volatile读,那不能重排序。
多线程
原子类
1 | do { |
c++ 实现 native method: compareAndSwapInt
1 | UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) |
LOCK_IF_MP multi processor
cmpxchg 不具有原子性,原子性 是通过加lock来保障
lock cmxchg 指令,lock保证 cmpchg操作某块内存时不允许其他 cpu 对该块做出修改
tips: lock在执行后面指令时锁定一个北桥信号而不采用锁总线的方式
JOL java object layout
1 | System.out.println(ClassLayout.parseInstance(o).toPrintable()); |
markword 8个字节, class pointer 4个字节, instance data, padding
指针长度 默认取决你的JVM,比如 64 bit, 即8个字节
1 | java -XX:+PrintCommandLineFlags -version |
但是由于开启了 UseCompressed*, 会被压缩为4个字节
而 Oop 指的是 ordinary object pointer, 指成员变量
markword 记录的信息
tips: 轻量级锁, 自旋锁, 无锁【傻逼叫法】 指的是同一种锁,只不过是各种花哨叫法
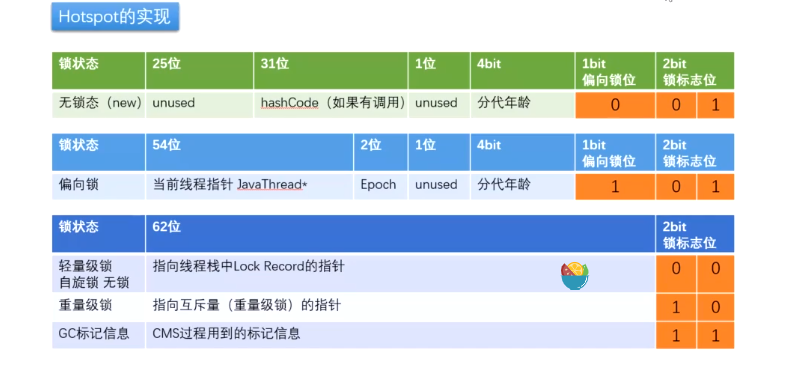
偏向锁:写 threadId 代表加锁进行占用,当发生竞争(即有线程来争抢该锁,一个线程即可)便会撤销偏向锁并开始升级为自旋锁,升级过程:竞争该锁的线程在各自的线程栈中生成 lock record, 然后各自通过自旋(即CAS:先读出锁内指针,然后将其改为自己 lock record 的地址,如果改回的过程中发现读出的状态没有改变,那么就成功抢到)的方式进行争抢,争抢成功后就会如上图,将原先的当前线程指针改为了指向 lock record 的指针。
上面明显看出一个问题,就是严重自旋,即如果某线程长时间持有锁那他人就会一直自旋(就是一个衡量标准,称为竞争加剧,比如线程超过了10次自旋, PreBlockSpin, 自旋线程数超过cpu核数的一半,1.6后加入自适应自旋:Adaptive Self Spinning,即由JVM自己抉择 ),这时候就会选择升级为重量级锁
严重自旋的问题:自旋就是while(), 旋就耗 cpu,所以可能会把 cpu 拉满
重量级锁会开个队列让线程等,等(也就是堵塞态)是不耗cpu的,操作系统会主动通知
0 0 1 未加锁
hashCodesynchronized(o)00 -> 轻量级锁,-XX:BiasedLockingStartupDelay=4, JVM 启动 4 秒后才会采用偏向锁模式,因为JVM启动需要执行很多 sync,那必然很多竞争,所以直接先用轻量锁跑(从而可以防一手大量的偏向锁的撤销和升级,白瞎资源)。
关于 epoch: 批量锁
锁降级:GC的时候,此时该锁除了GC线程已经不被其他线程访问了,没有意义
锁消除 lock eliminate: 比如局部变量
StringBuffer, 因为堆栈封闭,本身就没有线程安全考虑,所以会对其 append 方法进行锁消除
锁粗化:比如循环对
StringBuffer进行 append,JVM会将锁拿到循环外部
JIT: just in time
将热点代码直接转成机器码,避免解释从而提高执行效率
hsdis JVM反汇编插件
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly T
C1, C2优化
synchronized 过程
- class 文件: monitorenter monitorexit
- 执行过程自动升级
- lock comxchg

volatile
保证线程可见性

超线程:一个ALU对应多个PC|Registers,所谓得的四核八线程
Context switch:上下文切换:当仅有ALU,Register,PC三个组件时,同一时间仅能有一个线程执行,其他线程执行时需要将当前线程在这Register, ALU组件中的相关数据保存起来,然后才可以执行
Cache Line 64 字节:cpu 层的数据一致性是以 cache line 为单位的

缓存行对齐:disruptor 强行塞无意义变量来对齐缓存行避免过频繁而无意义的一致性追求

乱序执行
JVM 层级:内存屏障, 操作系统层级:Lock指令
系统底层实现一致性:MESI,如果不能(数据过大超出缓存行)的话就锁总线(万能方式)
系统底层实现有序性:内存屏障,sfence mfence lfence 等系统原语 或者 锁总线
单例模式:DCL, double check lock
1 | 0 new #2 <java/lang/Object> # new 出内存布局 |
如果 4 7 发生了指令重排序,那么就会出现引用判断不为 NULL 但实际没有构造成功,即线程使用了半初始化对象
如何实现禁止重排
字节码:ACC_volatile 标记
内存屏障:屏障两边的指令不可重排,保障有序性。JSR 内存屏障:LL,SS,LS,SL 按例解释 LL:L1,L2 不能重排,以此类推
hotspot 实现
- bytecodeinterpreter.cpp
1
2
3
4
5
6int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if(support_iriw...){
OrderAccess::fence();
}
}- orderAccess_bsd_x86.inline.hpp
1
2
3
4
5
6
7
8
9
10inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
}
}可见并非采用了系统原语,而是使用了 lock, 这是兼容保证,因为 mfence等并非所有系统都支持
强软弱虚
强引用:就是平常使用的引用,普通引用。引用存在就不会被回收
软引用:new SoftReferenceM<>(new byte[1024])
- Xmx=20m 最大堆内存 当堆内存占用不够的时候软引用就会被回收
- 应用:缓存,不用的时候释放掉,大不了再从数据库里取一次
弱引用:WeakReference
- 特点:垃圾回收器看到就会回收
- 应用:一次性,防止内存泄漏
虚引用:PhantomReferernce
- 特点:永远 get 不到
- 应用:管理堆外内存,给堆外内存对象挂一个虚引用,这样对象被gc时会将其相关信息放到队列中,特有的gc线程会监听这个队列,以此来管理堆外内存
ThreadLocal
应用:
- @Transactional 同一线程的多个方法调用时拿到同一个 connection
源码: Thread 里有个 map ThreadLocal<ThreadLocal, Object> 调用 ThreadLocal.set 方法时会取当前线程的 大map, 然后把自己和value放进去转成一个 entry<key, value>
1 | Entry extends WeakReference { super{k}} // 弱引用指向threadLocal |
防止内存泄露,如果强引用,那么t1没了也仍然不会被回收,因为entry key仍然引用它,但还是有个问题,就是value无法被访问了(key被指成null),因此必须调用一次 threadLocl.remove 方法
锁
程序抛出异常时,默认锁会被释放,这样就会被原来的那些个准备拿到这把锁的程序乱冲进来,程序乱入。
ReentrantLock
优于synchronized的地方:
- tryLock进行锁定,锁定与否都会继续执行方法(synchronized锁不到就阻塞了)
- lock.lockInterruptibly: A线程持有B线程想要的锁,B如果拿不到就会一直等,这时候可以用 interrupt 方法打断等待
- 公平锁:队列优先
- condition特性:本质上是多个等待队列
CountdownLatch
灵活版的join, await 插门闩,countdown拉门闩,拉多了就下来了
CycleBarrier
你加一我加一,加满就重来
Phaser 多阶段栅栏
重写onAdvance方法,前进,线程抵达这个栅栏的时候,所有的线程都满足了这个第一个栅栏的条件了onAdvance会被自动调用,目前我们有好几个阶段,这个阶段是被写死的,必须是数字0开始,onAdvance会传来两个参数phase是第几个阶段,registeredParties是目前这个阶段有几个人参加,每一个阶段都有一个打印,返回值false,一直到最后一个阶段返回true,所有线程结束,整个栅栏组,Phaser栅栏组就结束了
1 | arriveAndAwaitAdvance // 下个阶段 |
ReadWriteLock
读锁读共享,写锁写独占,读不放锁写别动,写不放锁都别动
Semaphore
传一个 permits, 每次acquire就减一,支持公平锁
Exchanger
两个线程交换信息,通信常用,或者游戏交换装备
Reentrantlock、CountDownLatch、CyclicBarrier、Phaser、ReadWriteLock、Semaphore,Exchanger都是用同一个队列,同一个类来实现的,这个类叫AQS
lock support
park,unpark原理:通过一个变量标识,变量在0 1之间切换(park unpark)大于0时就可继续执行
生产者消费者
为什么用while而不是用if? 因为当LinkedList集合中“馒头”数等于最大值的时候,if在判断了集合的大小等于MAX的时候,调用了wait()方法以后,它不会再去判断一次,方法会继续往下运行,假如在你wait()以后,另一个方法又添加了一个“馒头”,你没有再次判断,就又添加了一次,造成数据错误,就会出问题,因此必须用while。
AQS
共享一个state, state为0就可以抢,CAS抢到了就设置成1,重入就在1的基础上加1,以此递增
除了监控state外,还维护一个双向链表,这个链表的节点就是线程
acquire 方法:假如你要往一个链表上添加尾巴,尤其是好多线程都要往链表上添加尾巴,我们仔细想想看用普通的方法怎么做?第一点要加锁这一点是肯定的,因为多线程,你要保证线程安全,一般的情况下,我们会锁定整个链表(Sync),我们的新线程来了以后,要加到尾巴上,这样很正常,但是我们锁定整个链表的话,锁的太多太大了,现在呢它用的并不是锁定整个链表的方法,而是只观测tail这一个节点就可以了,怎么做到的呢?compareAndAetTail(oldTail,node),中oldTail是它的预期值,假如说我们想把当前线程设置为整个链表尾巴的过程中,另外一个线程来了,它插入了一个节点,那么仔细想一下Node oldTail = tail;的整个oldTail还等于整个新的Tail吗?不等于了吧,那么既然不等于了,说明中间有线程被其它线程打断了,那如果说却是还是等于原来的oldTail,这个时候就说明没有线程被打断,那我们就接着设置尾巴,只要设置成功了OK,compareAndAetTail(oldTail,node)方法中的参数node就做为新的Tail了,所以用了CAS操作就不需要把原来的整个链表上锁,这也是AQS在效率上比较高的核心
读acquireQueued()这个方法,这个方法的意思是,在队列里尝试去获得锁,在队列里排队获得锁,那么它是怎么做到的呢?我们先大致走一遍这个方法,首先在for循环里获得了Node节点的前置节点,然后判断如果前置节点是头节点,并且调用tryAcquire(arg)方法尝试一下去得到这把锁,获得了头节点以后,你设置的节点就是第二个,你这个节点要去和前置节点争这把锁,这个时候前置节点释放了,如果你设置的节点拿到了这把锁,拿到以后你设置的节点也就是当前节点就被设置为前置节点,如果没有拿到这把锁,当前节点就会阻塞等着,等着什么?等着前置节点叫醒你,所以它上来之后是竞争,怎么竞争呢?如果你是最后节点,你就下别说了,你就老老实实等着,如果你的前面已经是头节点了,说明什么?说明快轮到我了,那我就跑一下,试试看能不能拿到这把锁,说不定前置节点这会儿已经释放这把锁了,如果拿不着阻塞,阻塞以后干什么?等着前置节点释放这把锁以后,叫醒队列里的线程,我想执行过程已经很明了了,打个比方,有一个人,他后面又有几个人在后面排队,这时候第一个人是获得了这把锁,永远都是第一个人获得锁,那么后边来的人干什么呢?站在队伍后面排队,然后他会探头看他前面这个人是不是往前走了一步,如果走了,他也走一步,当后来的这个人排到了队伍的第二个位置的时候,发现前面就是第一个人了,等这第一个人走了就轮到他了,他会看第一个人是不是完事了,完事了他就变成头节点了,就是这么个意思。
VarHandle除了可以完成普通属性的原子操作,还可以完成原子性的线程安全的操作
在JDK1.9之前要操作类里边的成员变量的属性,只能通过反射完成,用反射和用VarHandle的区别在于VarHandle的效率要高的多,反射每次用之前要检查,VarHandle不需要,VarHandle可以理解为直接操纵二进制码,所以VarHandle反射高的多
并发容器
CopyOnWriteList
适合读多写少
BlockingQueue
- Title: Thread
- Author: ReZero
- Created at : 2020-09-19 12:22:00
- Updated at : 2025-05-26 05:53:22
- Link: https://rezeros.github.io/2020/09/19/thread/
- License: This work is licensed under CC BY-NC-SA 4.0.